SEED Dataset
A dataset collection for various purposes using EEG signals


Stimuli and Experiment

|
The duration of each film clip is approximately 3 to 4 minutes. Each film clip is well edited to create coherent emotion eliciting and maximize emotional meanings.
Each subject took part in the experiments three times (three sessions), and in each session there were 15 trials. Different video clips were used across the three sessions; therefore, each subject watched 15 × 3 = 45 clips in total. Each trial consisted of a 5-second preparatory hint, a 3-4 minutes video clip, a brief self-assessment interval, and a 15-second rest period. The order of presentation is arranged in such a way that two film clips that target the same emotion are not shown consecutively. For feedback, the participants were told to report their emotional reactions to each film clip by completing the questionnaire immediately after watching each clip. The detailed protocol is shown below:
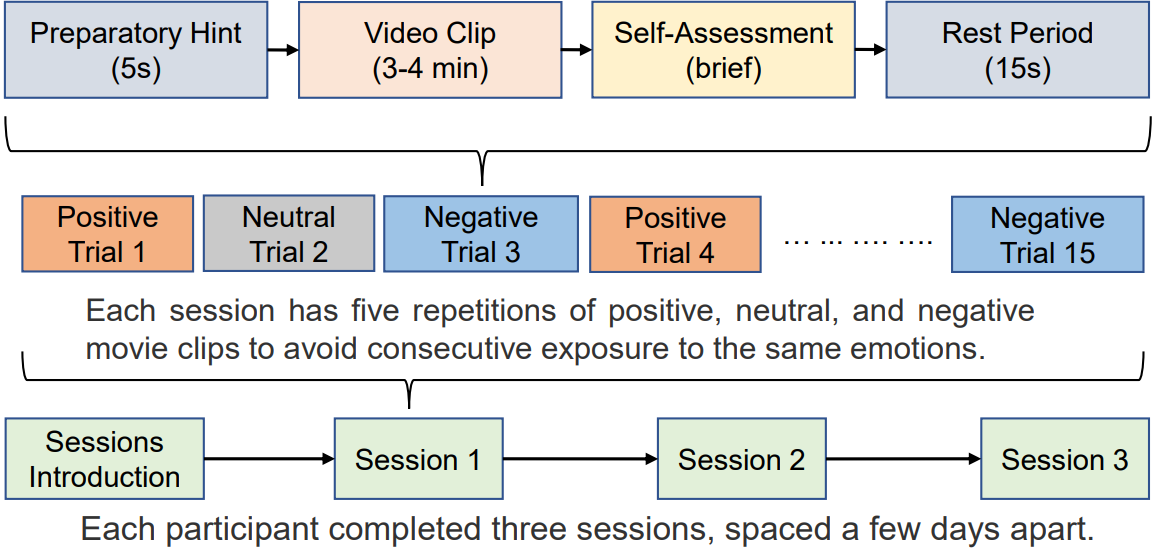
|
 |
Subjects
Twenty Myanmar subjects (11 males and 9 females; MEAN: 28.15, STD: 7.90) participated in the experiments. To protect personal privacy, we hide their names and indicate each subject with a number from 1 to 20. All participants were university students in Shanghai, China, originating from various regions of Myanmar.Dataset Summary
The details of SEED-MYA consists are shown below:- ‘Myanmar’ folder contains four subfolders.
- 01-EEG-raw: contains raw EEG signals of .cnt format with sampling rate of 1000Hz.
- 02-EEG-DE-feature: contains DE features extracted with 1-second and 4-second sliding window and source code to read the data.
- 03-Eye-tracking-excel: contains excel files of eye tracking information.
- 04-Eye-tracking-feature: contains eye tracking features in pickled format and source code to read the data.
- ‘code’ folder contains source code of models used in this paper.
- SVM, KNN, and logistic regression source code.
- DNN source code.
- Traditional fusion methods.
- Bimodal deep autoencoder.
- Deep canonical correlation analysis with attention mechanism.
- The source code is also available on GitHub.
- ‘information.xlsx’: contains information of experiments and subjects.
- For movie clips, positive, negative, and neutral emotions are labeled as 1, -1, and 0 respectively.
- To build classifiers, we used 2, 0, 1 for positive, negative, and neutral emotions, respectively (i.e., movie clip label plus one). For easier unimodal use, we saved the corresponding emotion labels in both EEG and eye movements feature files. In multimodal experiments, only one shared label is used since the eye-tracking labels are identical to the EEG labels for the same trial.
Download
References
If you feel that the dataset is helpful for your study, please add reference [1] to your publications.
1. K. P. P. Aung, H. -L. Yin, T. -F. Ma, W. -L. Zheng and B. -L. Lu, "SEED-MYA: A Novel Myanmar Multimodal Dataset for Enhancing Emotion Recognition," in IEEE Transactions on Affective Computing, vol. 16, no. 4, pp. 3183-3197, Oct.-Dec. 2025. [link] [BibTex]
2. K. P. Pa Aung, H. -L. Yin, T. -F. Ma, W. -L. Zheng and B. -L. Lu, "A Multimodal Myanmar Emotion Dataset for Emotion Recognition," 2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 2024, pp. 1-4. [link] [BibTex]