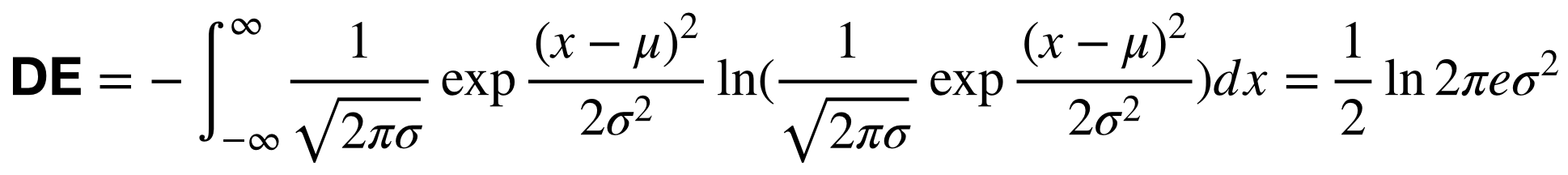SEED-IV 实验设定
通过初步研究,我们精心挑选了72个电影片段,这些片段能够引发快乐、悲伤、恐惧或中性情绪。
共有15名受试者参与了实验。
每位参与者在不同日期进行了3次实验,每次实验包含24个试验。
在一个试验中,参与者观看一个电影片段,同时使用62通道
ESI NeuroScan系统和
SMI眼动追踪眼镜收集他/她的脑电信号和眼动数据。
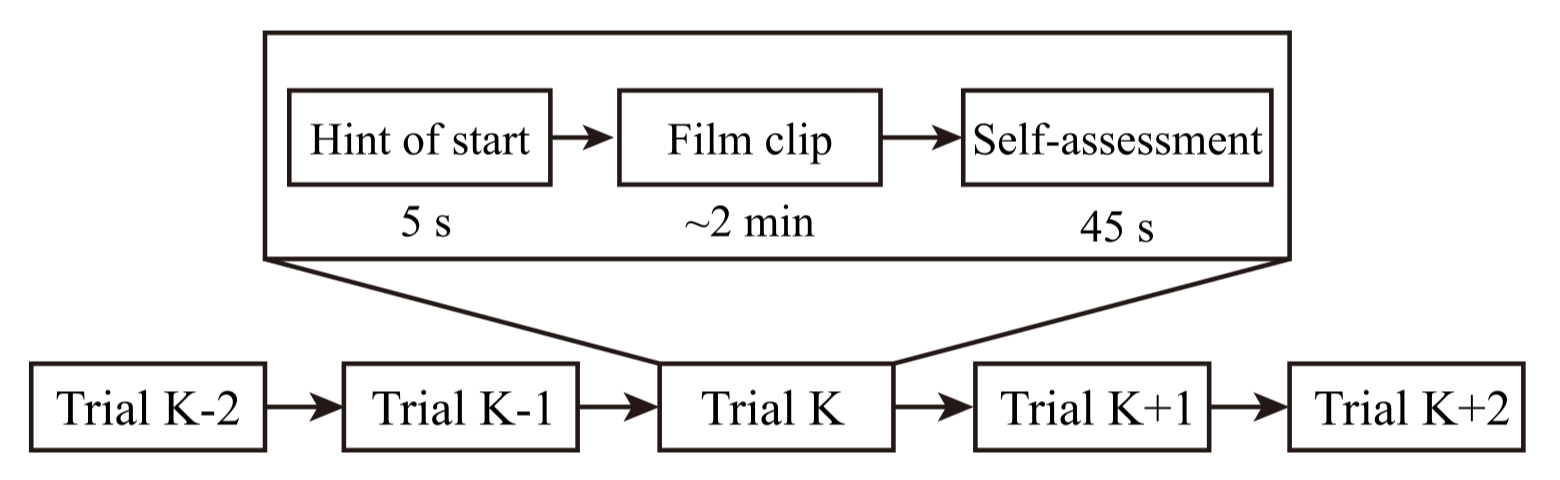
试验的时间安排如下所示:
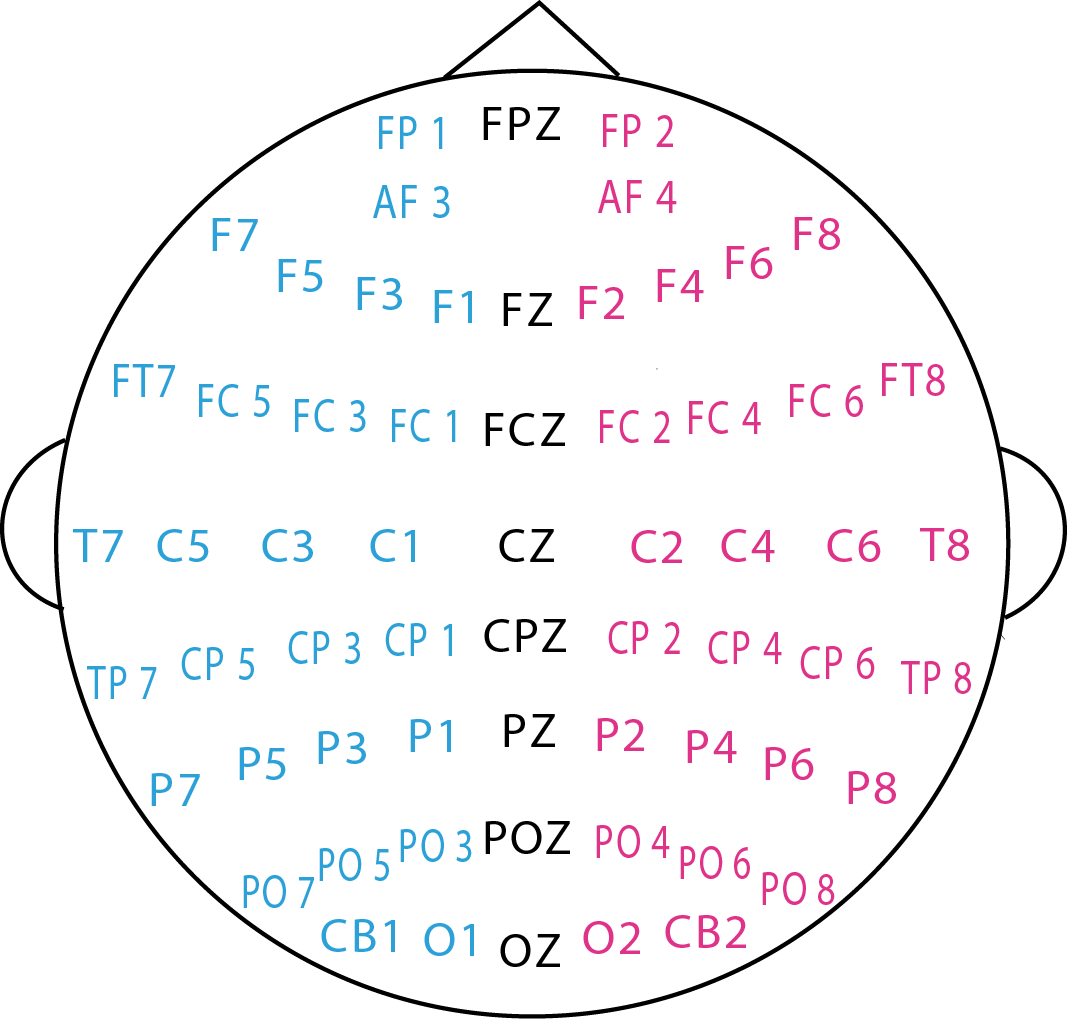
实验场景和相应的脑电电极放置如下图所示。
特征提取
每个实验会话被分割成4秒钟不重叠的片段。
在模型训练过程中,每个片段被视为一个数据样本。
脑电特征
对于脑电信号处理,原始脑电数据首先被降采样至200 Hz采样率。为了过滤噪声并去除伪影,脑电数据随后通过1 Hz到75 Hz之间的带通滤波器进行处理。之后,我们在5个频带内提取每个片段的功率谱密度(PSD)和差分熵(DE)特征:1)δ:1~4 Hz;2)θ:4~8 Hz;3)α:8~14 Hz;4)β:14~31 Hz;和5)γ:31~50 Hz。
随机变量
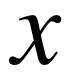
的PSD和DE计算如下:
我们假设脑电信号服从高斯分布:
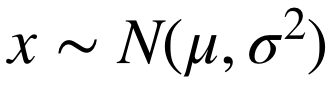
。
因此,DE特征的计算可以简化为:
眼动特征
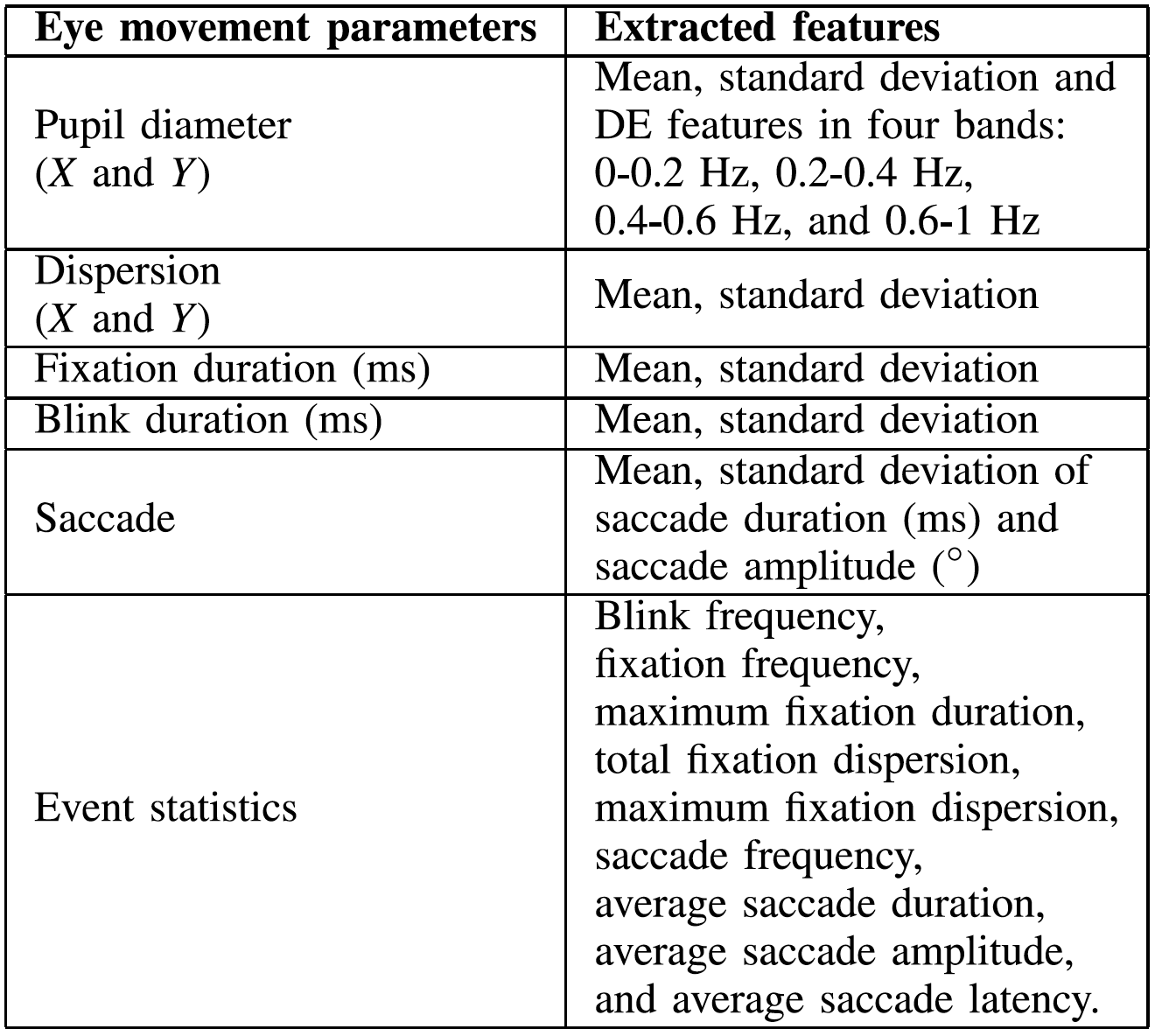
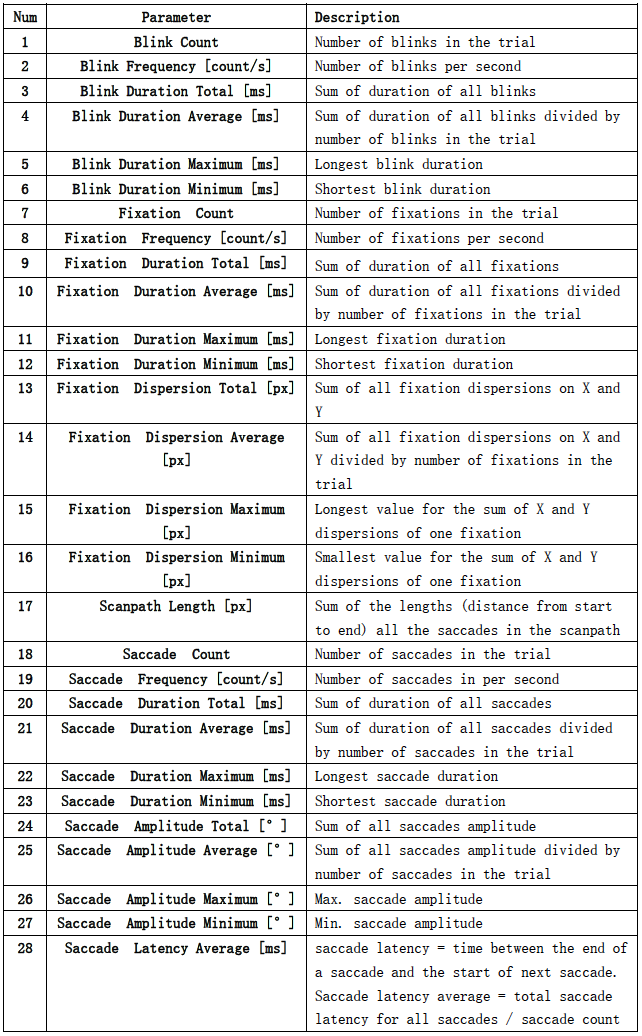
对于使用SMI眼动追踪眼镜收集的眼动信息,我们从文献中使用的各种详细参数中提取了不同特征,如瞳孔直径、注视、眼跳和眨眼。
眼动特征的详细列表如下所示。
数据集概述
在数据集文件夹中,您可以找到四个文件夹和2个文件。
-
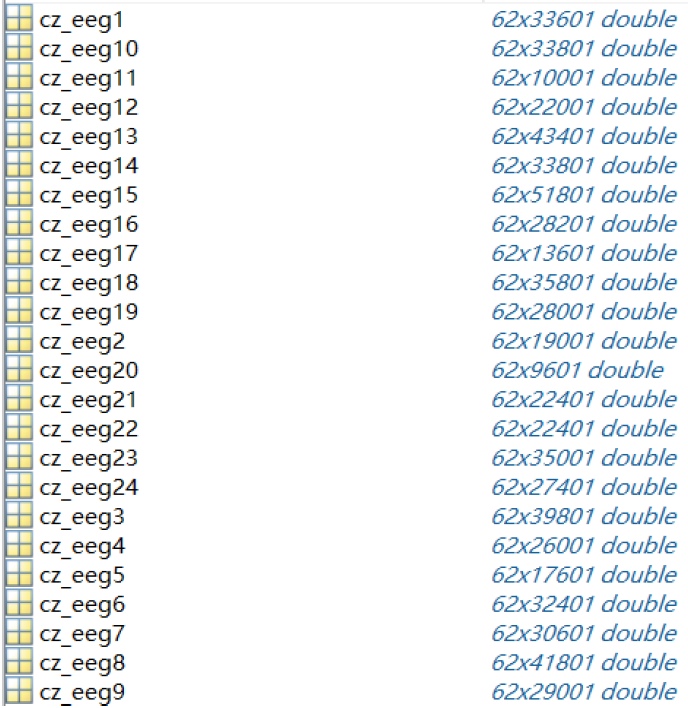
"eeg_raw_data"文件夹包含15名参与者的原始脑电信号。内部的3个文件夹名为'1'、'2'和'3',对应于3个实验会话。
每个".mat"文件(以{SubjectName}_{Date}.mat命名)存储了一个结构,其中包含名为"cz_eeg1"、"cz_eeg2"、...、"cz_eeg24"的字段,这些字段对应于24个试验中记录的脑电信号。下图展示了其中一个文件的架构。
-
"eeg_feature_smooth"文件夹具有与eeg_raw_data相同的结构。每个".mat"文件存储了一个结构,其中包含名为"{X}_{Y}{Z}"的字段。"X"表示特征类型,可以是"psd"或"de"。"Y"表示平滑方法的类型,可以是"movingAve"或"LDS"。
线性动态系统(LDS)和移动平均是两种不同的方法,用于过滤掉与脑电特征无关的噪声和伪影。
"Z"表示试验编号。
每个字段的形状为channel_number*sample_number*frequency_bands,换句话说,是62*W*5,
其中W表示该试验中的时间窗口数(不同试验的W不同,因为电影片段的长度不同)。
下图展示了其中一个文件的架构。
-
"eye_raw_data"文件夹包含用眼动追踪眼镜记录的眼动信息的原始数据。
每个会话有5个文件,格式如下:
- {SubjectName}_{Date}_blink.mat
- {SubjectName}_{Date}_event.mat
- {SubjectName}_{Date}_fixation.mat
- {SubjectName}_{Date}_pupil.mat
- {SubjectName}_{Date}_saccade.mat
每个文件的描述如下。
-
{SubjectName}_{Date}_blink.mat
其中一个文件的结构如下所示:
可以看到,文件中有24个矩阵,对应24个电影片段。例如,在第一个电影片段中,89表示眨眼次数,矩阵中的数据表示每次眨眼的持续时间[ms]。换句话说,受试者眨眼89次,并记录了每次眨眼的持续时间。
-
{SubjectName}_{Date}_event.mat
其中一个文件的结构如下所示:
可以看到,文件中有24个矩阵,对应24个电影片段。每个矩阵中的28表示28种事件类型,可以在下表中找到。
-
{SubjectName}_{Date}_fixation.mat
其中一个文件的结构如下所示:
可以看到,文件中有24个矩阵,对应24个电影片段。例如,在第一个电影片段中,439表示注视次数,矩阵中的数据表示注视持续时间[ms]。
-
{SubjectName}_{Date}_pupil.mat
其中一个文件的结构如下所示:
可以看到,文件中有24个矩阵,对应24个电影片段。例如,在第一个电影片段中,
439表示瞳孔记录次数,
4表示4个特征,即"平均瞳孔大小[px] X"、"平均瞳孔大小[px] Y"、
"分散度X"和"分散度Y"。
-
{SubjectName}_{Date}_saccade.mat
其中一个文件的结构如下所示:
可以看到,文件中有24个矩阵,对应24个电影片段。
例如,在第一个电影片段中,
444表示眼跳次数,2表示2个特征:"眼跳持续时间[ms]"和"振幅[°]"。
-
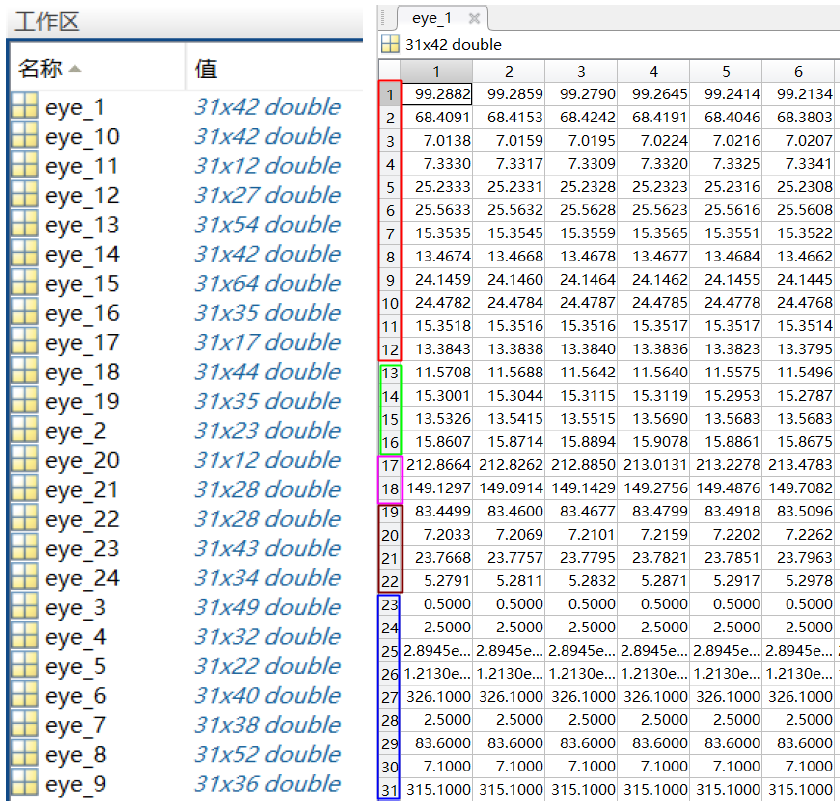
"eye_feature_smooth"文件夹包含从eye_raw_data文件夹中的文件提取的特征。
文件命名遵循"{SubjectName}_{date}.mat"格式。每个文件的结构如下图所示。
左侧部分显示24个字段;每个字段对应一个会话。
右侧部分显示其中一个字段中的数据矩阵。
每行对应一种特征类型,每列对应一个数据样本。
行号与特征类型的关系如下:
-
1-12:瞳孔直径(X和Y)
-
13-16:分散度(X和Y)
-
17-18:注视持续时间(ms)
-
19-22:眼跳
-
23-31:事件统计
-
"Channel Order.xlsx"文件列出了脑电电极布置图中通道名称的顺序,
与"eeg_raw_data"文件夹中提供的脑电原始数据中的通道顺序相对应。
-
"ReadMe.txt"文件展示了每个会话中每个试验的标签以及其他一些附加信息。
下载
 下载SEED-IV数据集
下载SEED-IV数据集
参考文献
如果您觉得该数据集对您的研究有帮助,请在您的出版物中添加以下参考文献。
Wei-Long Zheng, Wei Liu, Yifei Lu, Bao-Liang Lu, and Andrzej Cichocki, EmotionMeter:
A Multimodal Framework for Recognizing Human Emotions. IEEE Transactions on Cybernetics, Volume: 49, Issue: 3, March 2019, Pages: 1110-1122, DOI: 10.1109/TCYB.2018.2797176.
[link]
[BibTex]